The topic of how to accomplish zero-downtime deployments with websockets seems to come up fairly frequently, especially recently. As products evolve or get created we see the move from a fairly historical use of HTTP requests to utilising websockets for numerous things. A couple of those use cases are signalling for WebRTC or sending real-time events down to users.
I’ve developed a fair few of these types of systems now and the question of how we’re going to deal with deployments comes up. Do we deploy when no-one is using the service? This usually means an early start or a late night; that’s no fun for anyone and doesn’t feel very ‘agile’. What happens when something goes horribly wrong and we have to deploy while users are using the service? It’ll tell you what happens; chaos.
How do zero downtime deployments work with HTTP?
Let’s take a step back: how do people achieve zero downtime deployments with HTTP? Well, HTTP requests have short lives; we send a request in and we get a response back from the server. Depending on your HTTP response times, the life of a HTTP request could be a couple of hundred milliseconds to many many seconds - those many many seconds could be anything up to the TIMEOUT value in the browser; anything more than 60 and you’re really cutting it fine with browser timeouts.
That means that we can expect that we would have to theoretically deal with a request for up to 60 seconds. A 60 second request seems like a complete nightmare to me and if any API I built had 60 second response times I would cry. But the point is, it’s a finite number.
So one possible way to deal (there are many) with Zero Downtime deployments for a HTTP service would be to utilise Amazon’s Elastic Load Balancer service. When setup to deal with HTTP traffic, you can remove a host that sits behind the ELB from the available list, wait until all the requests have finished being dealt with (with an upper limit of 60 seconds for example), deploy your latest code and restart the service and place it back inside the ELB’s available list of hosts.
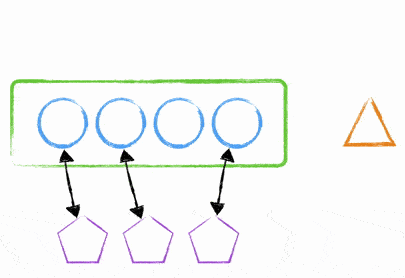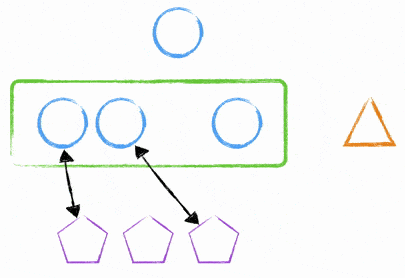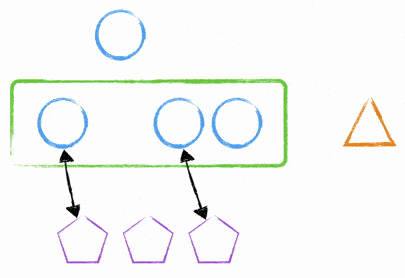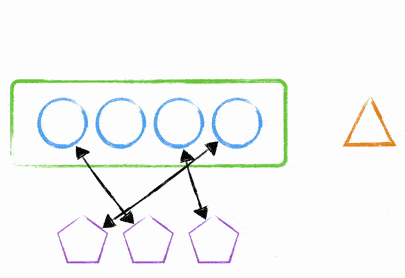
There are many other ways to deal with this. One way that I’ve done it in the past is to use Node.js’s clustering module. We were able to have a single ‘master’ process that talked to two child processes - the child processes were the ones dealing with requests and the master was merely deciding where to send the traffic.
By using this method, we were able to deploy new code to the instance, tell the master process to create two new child processes and tell the old child processes to stop accepting new traffic and then to shutdown after all requests were finished (or after a certain time limit - it wasn’t 60 seconds…. ). After the time limit of dealing with old requests, you’d be back to 2 child processes dealing with requests.
At no point would you incur downtime due to a process starting up / being missing.
Another way to deal with this would be to utilise nginx’s upstream proxy method, where you can give the proxy many different URLs to call, with different methods of load balancing available.
But what about websocket zero-downtime deployments?
There is no such thing as pure websocket zero-downtime deployments. I’m sorry.
But you can 100% deal with the websocket in a way that you can deploy whenever you like; with no downtime for the user; and that’s all that matters isn’t it?
Let’s take a typical scenario (that I see all the time) to deal with deployments for websocket related services.
For websockets to work through Amazon’s ELB service, you have to set the ELB into TCP mode. This comes with a distinct disadvantage - as soon as you take a host out from an ELB while it’s in TCP mode, the connection gets dropped. the ELB kills the connection. This is completely different behaviour to how it deals with HTTP traffic.
This means you can’t remove your host from the Load Balancer until it’s clear of websockets. Depending on your setup and health checks, it’s most likely that you can’t just tell your Node.js app to stop accepting new connection; that would mean the ELB would see the host as bad and remove it the available hosts list anyway.
This scenario expects that your node.js application can cope with more than 1 host dealing with websockets and that websocket sessions can be shared between the processes etc - or that you don’t care about saving auth sessions etc.
So in this scenario you have to deploy to the instance while it’s in the ELB and only ever remove a host from the ELB when it’s really unhealthy - cutting off those websockets midstream if there are any.
So how do you deploy to an instance, while it’s still in the ELB without cutting off any websockets? It’s quite simple really - you either use the clustering mechanism I talked about earlier or you start up a new node.js process (with your newly deployed code) on a different port and add it into your nginx upstream proxy configuration. This means your instance can now handle more websockets; but the old process is still running and accepting connections. How does this help? Quite simply, you now tell the old process to stop accepting connections and send a unix signal to the process; this signal then gets interpreted as an instruction to broadcast an event to all your websocket clients. Your client library needs to understand that this broadcasted message means disconnect when it’s good to do so and reconnect.
What will now happen is that the client will reconnect to any of your available hosts with your new processes running updated code. There’s been no cut off of websocket midstream and everything was handled gracefully. Once your old processes don’t have any more open connections, they can shut themselves down and then you can remove the old process from your upstream proxy configuration in nginx.
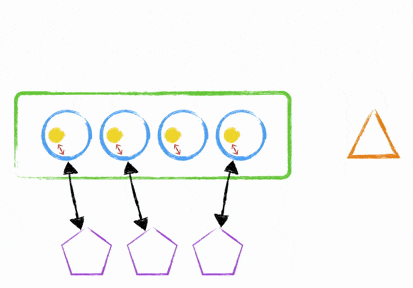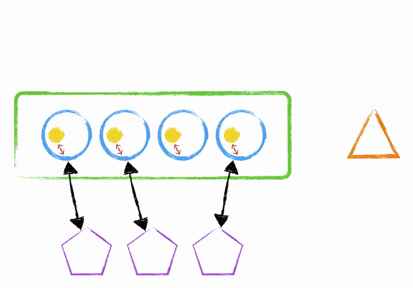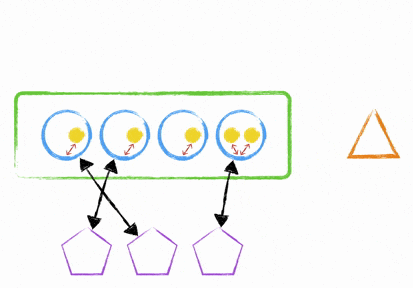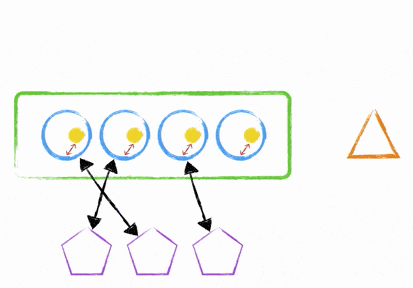
It’s not simple.
No, it’s not simple but it does enable you to gracefully handle all your client disconnects, etc, within your application. There are other ways that re-incarnate the same kind of methodology - you could spin up completely new instances every time you deploy for example and gracefully migrate your websocket clients. There are other things you’d need to think about too; does your new code need something new in your client library? Does your client library need to know about a new event? If so how do you deal with that? Would you disconnect the websocket, re-download the newly deployed client library asynchronously and then re-connect using the new library version? These problems aren’t new ones to the typical HTTP client issues, they’re just a little more complex probably.
Do you get zero-downtime deployments with a service utilising websockets? Have you gone about it in a different way or even want to call me out on some details here? Let us know in the comments.